
360点选识别
360 点选实战(yolvo8+孪生)
过程
我们使用 python 脚本 爬取保存大概 100 多张图片即可,放在本地文件夹下。
接着使用X-AnyLabeling 进行数据标注。
主要注意的是需要导出中转为 yolo 格式,这样的话可以自动转为 yolo 可识别的 txt 文件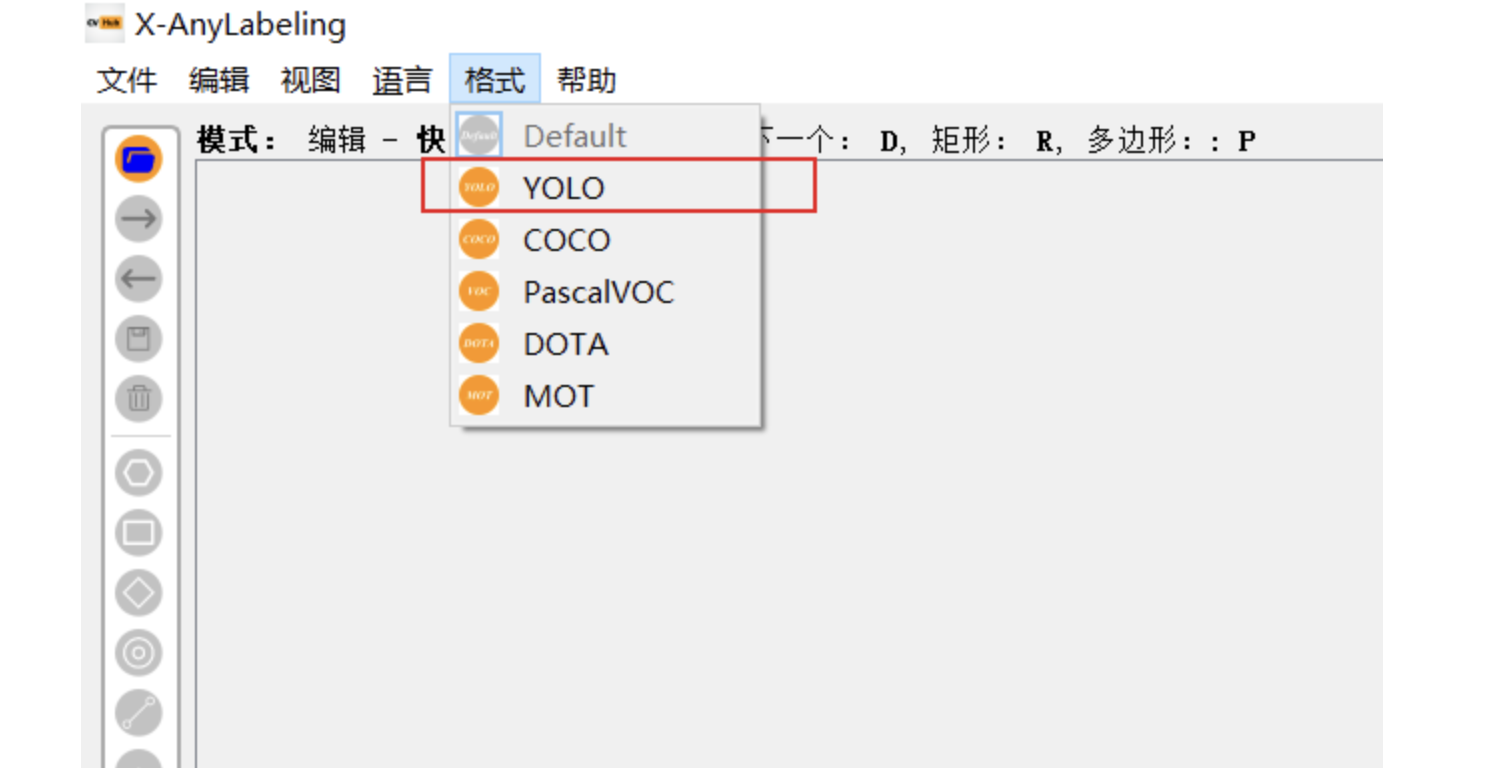
接下来我们打标就可,因为是做孪生,所以我们不需要详细分类,给每个标签打上固定的标签即可,我这里是 labels。 依次标注即可,360 这个并没有太多的图片,基本都是相同种类重复的偏多,就是改个字体。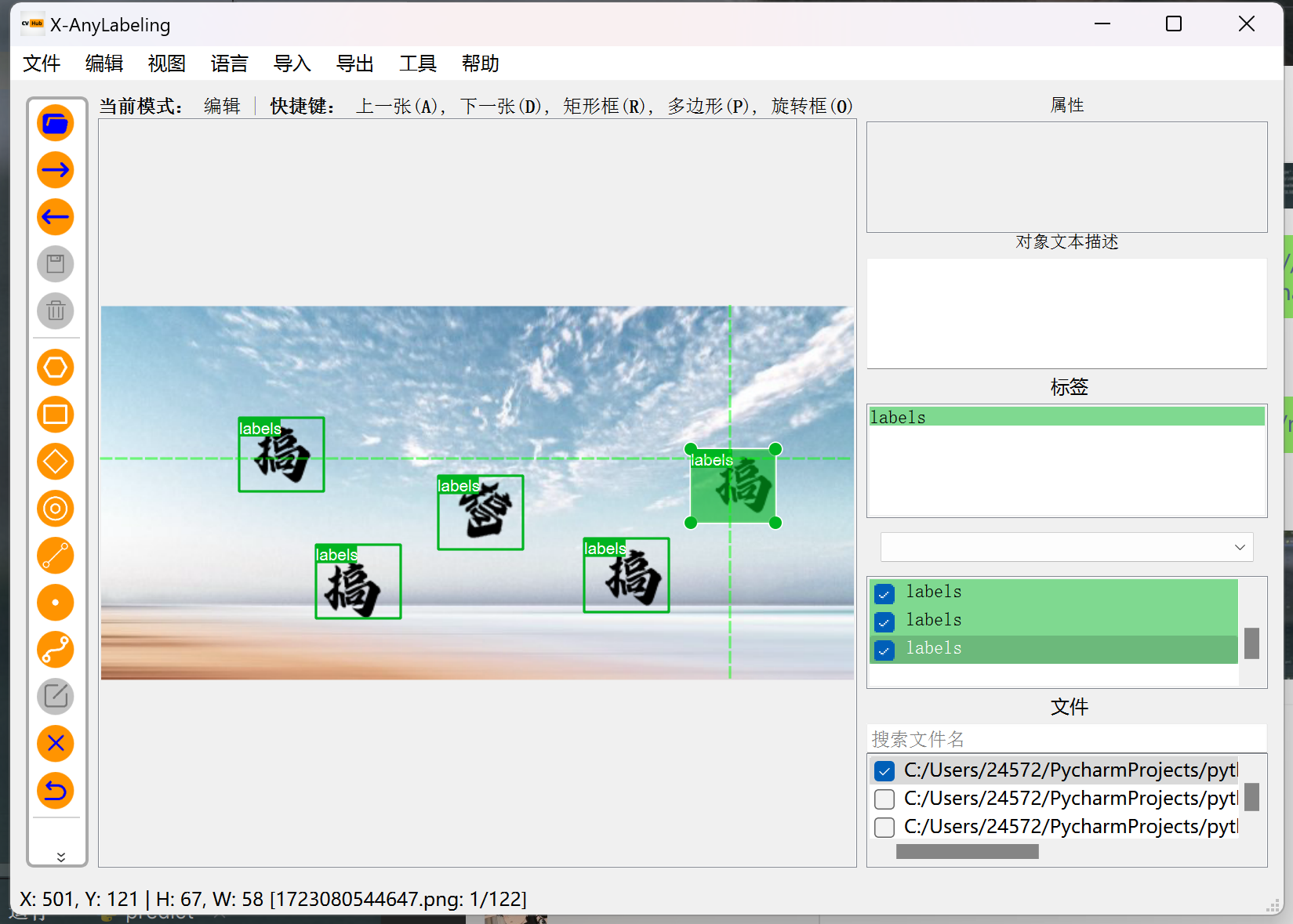
打完标之后我们就可以利用一个脚本 进行格式转化了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
# -*- coding: utf-8 -*-
import json
import os
import random
import shutil
def json2yolo(json_folder, class_dic):
"""讲labelme的json文件转成txt文件 {"notch": '0'}"""
file_list = os.listdir(json_folder)
txt_folder = os.path.dirname(json_folder) + "\labels_txt"
if not os.path.exists(txt_folder):
os.makedirs(txt_folder)
json_file_list = [x for x in file_list if ".json" in x] # 获取所有json文件的路径
for p in json_file_list:
json_file = os.path.join(json_folder, p)
with open(json_file, encoding='utf-8') as f:
data = json.loads(f.read())
img_w = data["imageWidth"] # 获取json文件里图片的宽高
img_h = data["imageHeight"]
all_line = ''
for i in data["shapes"]:
# 归一化坐标点。并得到cx,cy,w,h
[[x1, y1], [x2, y2]] = i['points']
x1, x2 = x1 / img_w, x2 / img_w
y1, y2 = y1 / img_h, y2 / img_h
cx = (x1 + x2) / 2
cy = (y1 + y2) / 2
w = abs(x2 - x1)
h = abs(y2 - y1)
# 将数据组装成yolo格式
line = f"%s %.4f %.4f %.4f %.4f\n" % (class_dic[i['label']], cx, cy, w, h) # 生成txt文件里每行的内容
all_line += line
# print(all_line)
txt_file = os.path.join(txt_folder, p.replace('json', 'txt'))
with open(txt_file, 'w', encoding='utf-8') as fh:
fh.write(all_line)
# json2yolo(r'D:\Web_Decryption\SEASON\0527\test', {"殊":"0","乡":"1","趋":"2",})
def shape2id(json_folder):
classes2id = {}
classes_all = set()
num = 0
jsons = os.listdir(json_folder)
for i in jsons:
json_path = os.path.join(json_folder, i)
with open(json_path, 'r', encoding="utf-8") as f:
json_data = json.load(f)
# print(json_data['shapes'])
for j in json_data['shapes']:
if j['label'] not in classes2id:
classes2id[j['label']] = num
num += 1
classes_all.add(j['label'])
print(classes2id)
print("所有分类", classes_all)
return classes2id
# shape2id(r'D:\day_soft\Labelme\custom_model\lably')
def split_images_floder(img_dir, label_dir, img_suffix='.png'):
"""
将数据集划分为训练集,验证集,测试集
"""
# 1.确定原图片数据集路径
datasetimg_dir = img_dir
# 确定原label数据集路径
datasetlabel_dir = label_dir
# 2.确定数据集划分后保存的路径
_f = os.path.dirname(img_dir)
split_dir = os.path.join(_f, "dataset")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
dir_list = [train_dir, valid_dir, test_dir]
image_label = ['images', 'labels']
for i in range(len(dir_list)):
for j in range(len(image_label)):
new_dir = os.path.join(dir_list[i], image_label[j])
if not os.path.exists(new_dir):
os.makedirs(new_dir)
# 3.确定将数据集划分为训练集,验证集,测试集的比例
train_pct = 0.9
valid_pct = 0.1
test_pct = 0
# 4.划分
imgs = os.listdir(datasetimg_dir) # 展示目标文件夹下所有的文件名
imgs = list(filter(lambda x: x.endswith(img_suffix), imgs)) # 取到所有以.png结尾的文件,如果改了图片格式,这里需要修改
random.shuffle(imgs) # 乱序路径
img_count = len(imgs) # 计算图片数量
train_point = int(img_count * train_pct) # 0:train_pct
valid_point = int(img_count * (train_pct + valid_pct)) # train_pct:valid_pct
for i in range(img_count):
if i < train_point: # 保存0-train_point的图片到训练集
out_dir = os.path.join(train_dir, 'images')
label_out_dir = os.path.join(train_dir, 'labels')
elif i < valid_point: # 保存train_point-valid_point的图片到验证集
out_dir = os.path.join(valid_dir, 'images')
label_out_dir = os.path.join(valid_dir, 'labels')
else: # 保存test_point-结束的图片到测试集
out_dir = os.path.join(test_dir, 'images')
label_out_dir = os.path.join(test_dir, 'labels')
target_path = os.path.join(out_dir, imgs[i]) # 指定目标保存路径
src_path = os.path.join(datasetimg_dir, imgs[i]) # 指定目标原图像路径
label_target_path = os.path.join(label_out_dir, imgs[i][0:-4] + '.txt')
label_src_path = os.path.join(datasetlabel_dir, imgs[i][0:-4] + '.txt')
shutil.copy(src_path, target_path) # 复制图片
shutil.copy(label_src_path, label_target_path) # 复制txt
print('train:{}, valid:{}, test:{}'.format(train_point, valid_point - train_point, img_count - valid_point))
#split_images_floder(r"C:\Users\24572\PycharmProjects\pythonProject\360click\images", r"C:\Users\24572\PycharmProjects\pythonProject\360click\labels")
def make_yolo_yaml(yaml_name, image_dir, class_names):
"""生成yolo格式的yaml文件"""
if not os.path.exists(yaml_name):
os.makedirs(yaml_name)
nums = len(class_names)
# 生成数据集配置.yaml
with open(yaml_name, "w", encoding='utf-8') as f:
f.write(f"train: {image_dir}/train/images\n")
f.write(f"val: {image_dir}/valid/images\n")
f.write(f"test: {image_dir}/test/images\n")
f.write("\n")
f.write(f"nc: {nums}\n")
f.write(f"names: {class_names}\n")
make_yolo_yaml(r"C:\Users\24572\PycharmProjects\pythonProject\360click\font.yaml", r'C:\Users\24572\PycharmProjects\pythonProject\360click\dataset', ["labels"])
def create_valid_test_folder(image_dir, labels_dir, img_suffix='.jpg'):
"""
:param image_dir: D:\Yzmtrain\yzmdata\dyclick_524\images_all
:param labels_dir: D:\Yzmtrain\yzmdata\dyclick_524\labels_all
:param img_suffix:
:return:
"""
_folder = os.path.dirname(image_dir)
for dirs in ['train/images', 'train/labels', 'valid/images', 'valid/labels', 'test/images', 'test/labels']:
try:
os.makedirs(os.path.join(image_dir, dirs))
except FileExistsError:
print(f'{dirs} 目录已存在')
image_file_list = os.listdir(image_dir)
total_num = len(image_file_list)
train_num = int((total_num-10)/7)
valid_num = total_num - 10 - train_num
for img_name in image_file_list[:10]:
json_name = img_name.replace(img_suffix, ".json")
img_src = os.path.join(image_dir, img_name)
dst_images = os.path.join(f"{_folder}/test/images", img_name)
os.rename(img_src, dst_images)
labels_src = os.path.join(labels_dir, json_name)
dst_labels = os.path.join(f"{_folder}/test/labels", json_name)
os.rename(labels_src, dst_labels)
def rename_file():
aa_all = {}
json_folder = "D:\Yzmtrain\yzmdata\hanzi_1\hanzi\hanzi\js11"
file_list = os.listdir(json_folder)
json_file_list = [x for x in file_list if ".json" in x] # 获取所有json文件的路径
for p in json_file_list:
json_file = os.path.join(json_folder, p)
image_file = json_file.replace("\js11", '').replace("json", "jpg")
with open(json_file, encoding='utf-8') as f:
data = json.loads(f.read())
print(json_file, image_file)
print(p, data['shapes'][0]['label'])
aa_all[p] = f"{data['shapes'][0]['label']}_{p[2:]}"
os.rename(json_file, f"D:\Yzmtrain\yzmdata\hanzi_1\hanzi\hanzi\js11\\{data['shapes'][0]['label']}_{p[2:]}")
os.rename(image_file, f"D:\Yzmtrain\yzmdata\hanzi_1\hanzi\hanzi\\{data['shapes'][0]['label']}_{p[2:]}".replace("json", "jpg"))
print(aa_all)
# rename_file()
# _folder = "D:\Yzmtrain\yzmdata\chinese"
# file_list = os.listdir(_folder)
# json_file_list = [x for x in file_list if ".json" in x] # 获取所有json文件的路径
# for p in json_file_list:
# json_file = os.path.join(_folder, p)
# os.rename(json_file, f"D:\Yzmtrain\yzmdata\chinese_json\\{p}")运行 split_images_floder 之后本地就会生成 一些文件夹,其中存放着划分的验证机和数据集
之后创建一个 font.yaml 的文件 在运行 make_yolo_yaml 就生成了支持 yolov8 训练的配置文件。
以上都大功告成之后,我们就可以开始进行训练了
1
2
3
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
results = model.train(data="font.yaml", epochs=200, cache=True, imgsz=320, batch=16, workers=0, device='cuda')之后我们会在当前 runs/detect/train/weights 得到一个 best.pt 文件 这就是我们后面需要识别和切割的模型了
我们利用Siamese-pytorch 我们本地下载 GitHub 中提供的模型,并把它放入 model_data 中,然后我们运行 predict.py 文件 来测试环境是否正确。 如果没问题那么就可以开始我们正式训练了.
首先我们来明确一下思路。
需要先获得一张图片
之后要利用 yolov8 进行识别切割,并保存在一个文件夹中
我们要遍历切割后的文件夹,并且以某一张图片来作为基准,与其他对比。同时获取裁切后的坐标,方便后续找到不同图片时也能得到对应坐标。
情况 1:对比后找到其他图片为相似度最小的一张
情况 2:当前这张要对比的图片与其他 4 张都不同,是特立独行的图片
4.提交验证,有加密处理加密,有验证提交验证数据包。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
import json
import random
import time
import execjs
from PIL import Image
from ultralytics import YOLO
from siamese import Siamese
import cv2
import numpy as np
import os
import requests
token = 'e7e3456c9521de075c0ed00a7d6d7480'
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"pragma": "no-cache",
"referer": "https://sqhd.u.360.cn/",
"sec-ch-ua": "\"Not)A;Brand\";v=\"99\", \"Microsoft Edge\";v=\"127\", \"Chromium\";v=\"127\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "script",
"sec-fetch-mode": "no-cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0"
}
cookies = {
"__huid": "11xEyO13c+M4dgY6TiYNLPb9LRVgaku/GXVMp/qF0GMNQ=",
"__guid": "230272478.3358358338768799744.1704856402001.2004",
"__NS_Q": "u%3Dyv083024%26n%3D%26le%3D%26m%3DZGp3WGWOWGWOWGWOWGWOWGWOZGL4%26qid%3D3403077592%26im%3D1_t01923d359dad425928%26src%3Dpcw_quake%26t%3D1",
"Q": "u%3Dyv083024%26n%3D%26le%3D%26m%3DZGp3WGWOWGWOWGWOWGWOWGWOZGL4%26qid%3D3403077592%26im%3D1_t01923d359dad425928%26src%3Dpcw_quake%26t%3D1",
"__DC_gid": "208211024.767422413.1715657472373.1715657472383.2",
"T": "s%3Dfe966e73df014d7fc952331d9cd492cb%26t%3D1715925046%26lm%3D%26lf%3D4%26sk%3D6d22cff2c2004dc594d8a9cd5674ca07%26mt%3D1715925046%26rc%3D%26v%3D2.0%26a%3D1",
"__NS_T": "s%3Dfe966e73df014d7fc952331d9cd492cb%26t%3D1715925046%26lm%3D%26lf%3D4%26sk%3D6d22cff2c2004dc594d8a9cd5674ca07%26mt%3D1715925046%26rc%3D%26v%3D2.0%26a%3D1"
}
# 获取验证码图片并且保存图片和一些提交验证的参数。
def get():
url = "https://captcha.bpd.360.cn/v1/get"
params = {
"appid": "LS3yVZANuLCqvFn1IWNGVNeC37ExAbuL",
"token": token,
"ty": "3",
}
response = requests.get(url, headers=headers, cookies=cookies, params=params).json()
print(response)
pic_url = response["data"]["pic"]["bg"]
ftoken = response["data"]["ftoken"]
pic_ = requests.get(pic_url,headers=headers)
with open(f"./img/{int(time.time()*1000)}.png",'wb') as f:
f.write(pic_.content)
print("完成")
return pic_url,ftoken
pic_url,ftoken = get()
# 加载YOLO模型
model = YOLO('best.pt')
# 利用YOLO进行 指定坐标裁切
def cai_save(img_big):
results = model.predict(img_big)
img_big_cai = [] # 裁剪图片并保存在列表中
center_coordinates = {}
for idx, box in enumerate(results[0].boxes.xyxy):
box = list(map(int, box))
img_c = img_big[box[1]:box[3], box[0]:box[2]]
img_big_cai.append(img_c)
center_x = int((box[0] + box[2]) / 2)
center_y = int((box[1] + box[3]) / 2)
#获取裁切后的坐标
center_coordinates[f'qie_{idx + 1}'] = {'center_x': center_x, 'center_y': center_y}
# 保存裁剪后的图片
folder_path = './cai_big_images'
if not os.path.exists(folder_path):
os.makedirs(folder_path)
for idx, img_array in enumerate(img_big_cai, start=1):
# 生成文件名
filename = f"qie_{idx}.jpg"
filepath = os.path.join(folder_path, filename)
# 保存图片
cv2.imwrite(filepath, img_array)
return center_coordinates
dir_path = r'E:\Siamese-pytorch\img'
files = os.listdir(dir_path) #遍历目录下的图片文件
print(files)
for file in files:
img = cv2.imread(os.path.join(dir_path, file))
center_coordinates = cai_save(img)
print(center_coordinates) #输出坐标
print("全部切分完成,开始孪生对比")
# 创建一个 Siamese 类的实例
model = Siamese()
def compare_with_reference(folder_path, reference_filename):
min_similarity = float('inf') # 存储与参考图片相比最不相似的图片的相似度
unique_image_filename = None # 存储最不相似的图片文件名
reference_image = Image.open(os.path.join(folder_path, reference_filename))
for filename in os.listdir(folder_path):
if filename.endswith(".jpg") or filename.endswith(".jpeg"):
if filename == reference_filename:
continue # 跳过参考图片本身
# 加载图片
image_path = os.path.join(folder_path, filename)
image = Image.open(image_path)
# 使用模型计算相似度概率 孪生识别
probability = model.detect_image(reference_image, image)
probability_value = probability.item()
# 如果当前图片的相似度低于之前记录的最低相似度,则更新
if probability_value < min_similarity:
min_similarity = probability_value
unique_image_filename = filename
# 返回最不相似的图片文件名及其相似度
return unique_image_filename, min_similarity
folder_path = r"E:\Siamese-pytorch\cai_big_images" #裁切后图片位置
unique_image_filename, min_similarity = compare_with_reference(folder_path, 'qie_2.jpg') #打开参考图片 qie_2.jpg
if unique_image_filename is not None:
unique_image_key = unique_image_filename.replace(".jpg","")
unique_image_coordinates = center_coordinates.get(unique_image_key,None)
print(f"特立独行的图片是 {unique_image_filename},相似度为 {min_similarity},中心坐标为: {unique_image_coordinates}")
# # 显示特立独行的图片
# unique_image_path = os.path.join(folder_path, unique_image_filename)
# unique_image = cv2.imread(unique_image_path)
# cv2.imshow('Unique Image', unique_image)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
print(unique_image_coordinates)
#####网站加密的轨迹坐标处理
x = unique_image_coordinates['center_x']
y = unique_image_coordinates['center_y']
final_list = []
print('x', x)
print('y', y)
# 网页实际缩放了图片 比例是1/2 所以要乘0.5 对应网页
entry = {
"x": int(x * 0.5),
"y": int(y * 0.5),
"t": int(time.time() * 1000) + random.randint(0, 150), # 固定时间戳
"type": "mousedown" # 固定操作类型
}
final_list = [entry]
guiji = json.dumps(final_list)
print(guiji)
# aes加密
d = execjs.compile(open('./1.js', 'r', encoding="utf-8").read()).call('get_d', guiji)
print(d)
#提交验证
url = "https://captcha.bpd.360.cn/v1/verify"
params = {
"appid": "LS3yVZANuLCqvFn1IWNGVNeC37ExAbuL",
"token": token,
"ftoken": ftoken,
"d": d,
"scale": "0.5",
"ty": "3",
"src": "",
"imgUrl": pic_url,
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
print(response.text)结果验证
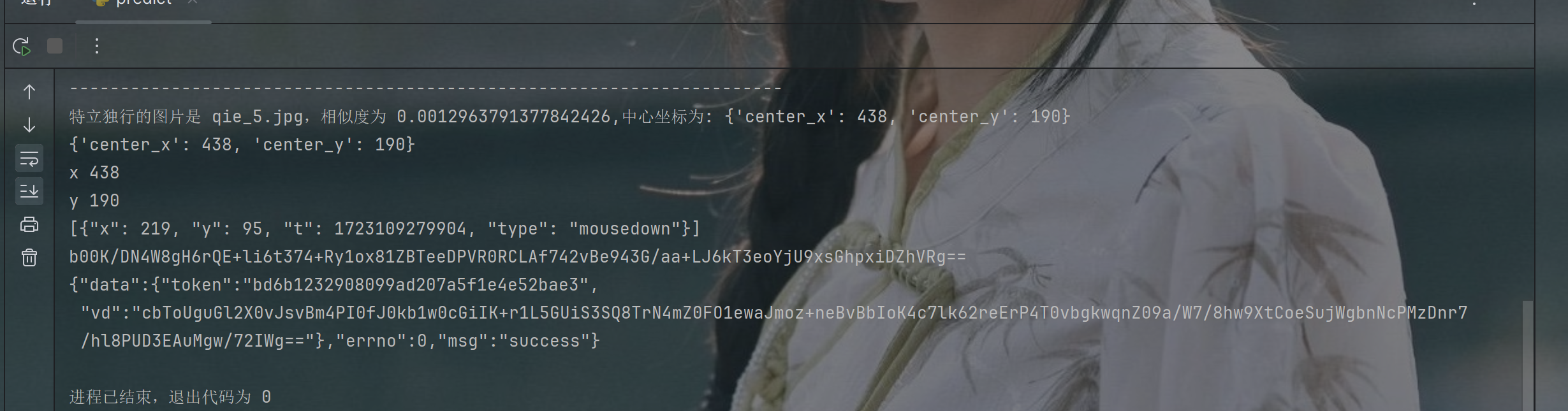
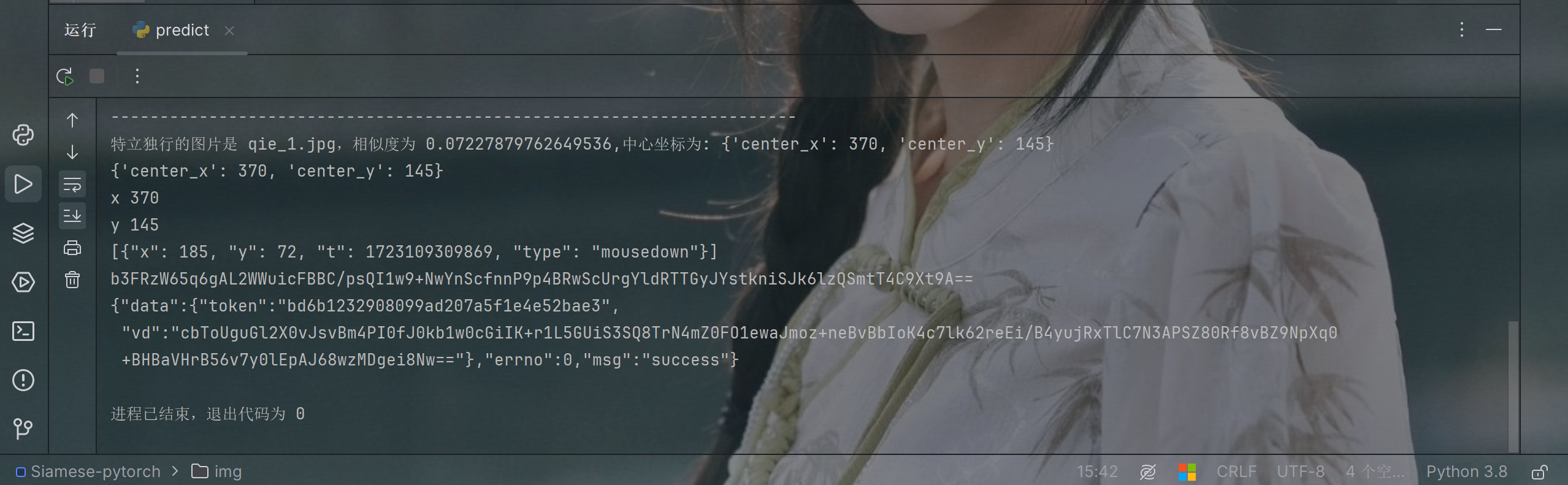
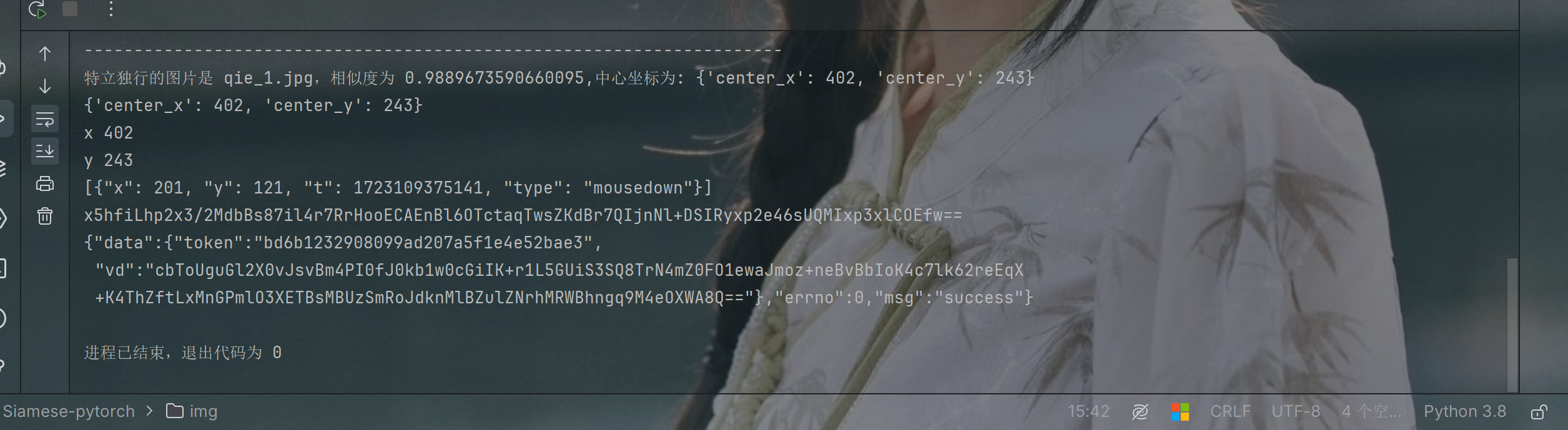
到此完结。 通过了还是可以的